Sobre
Jaime S. Cardoso, licenciado em Engenharia e Eletrotécnica e de Computadores em 1999, Mestre em Engenharia Matemática em 2005 e doutorado em Visão Computacional em 2006, todos pela Universidade do Porto. Professor Associado com agregação na Faculdade de Engenharia da Universidade do Porto (FEUP) e Investigador Sénior em 'Information Processing and Pattern Recognition' no Centro de Telecomunicações e Multimédia do INESC TEC.
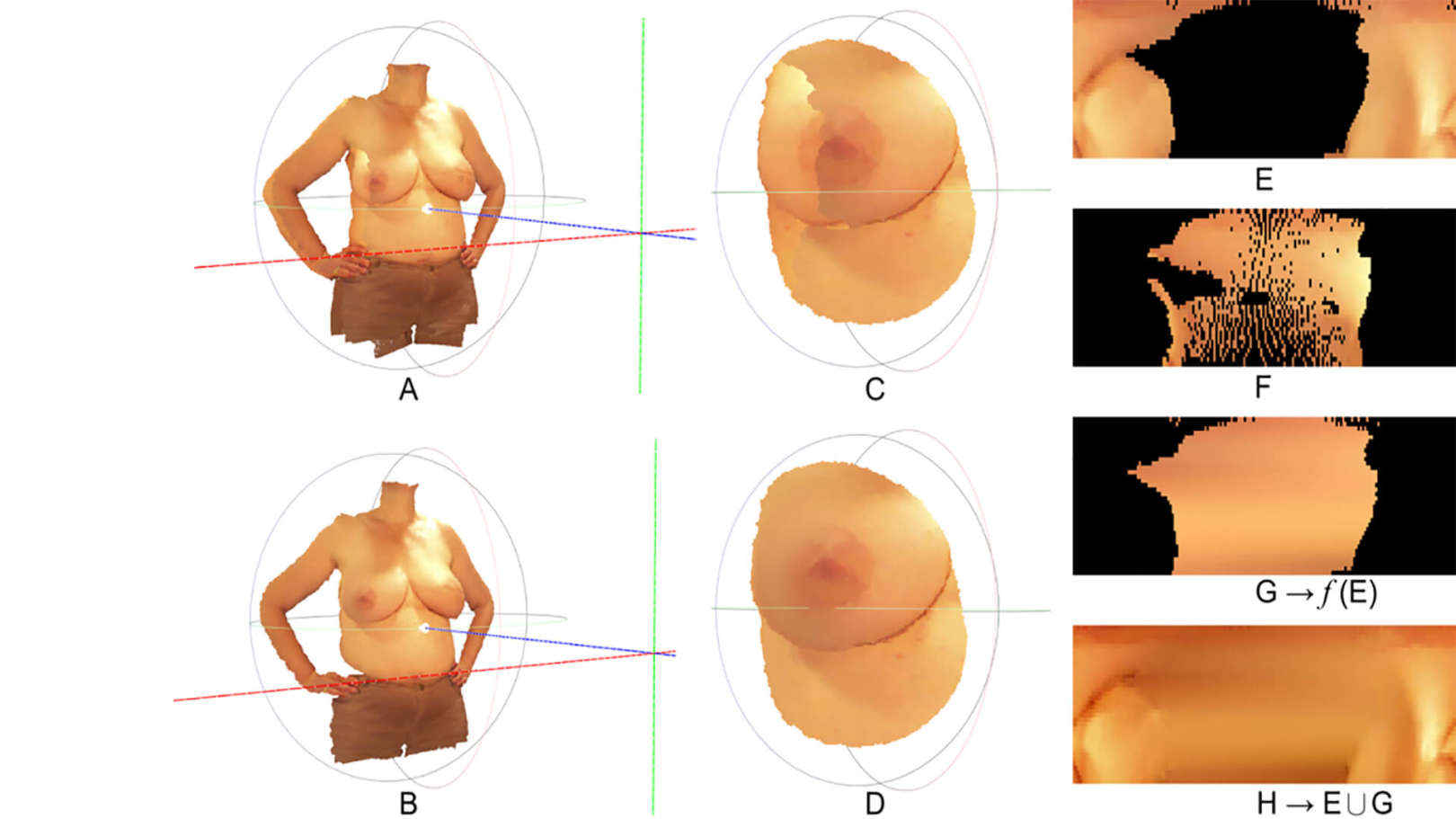
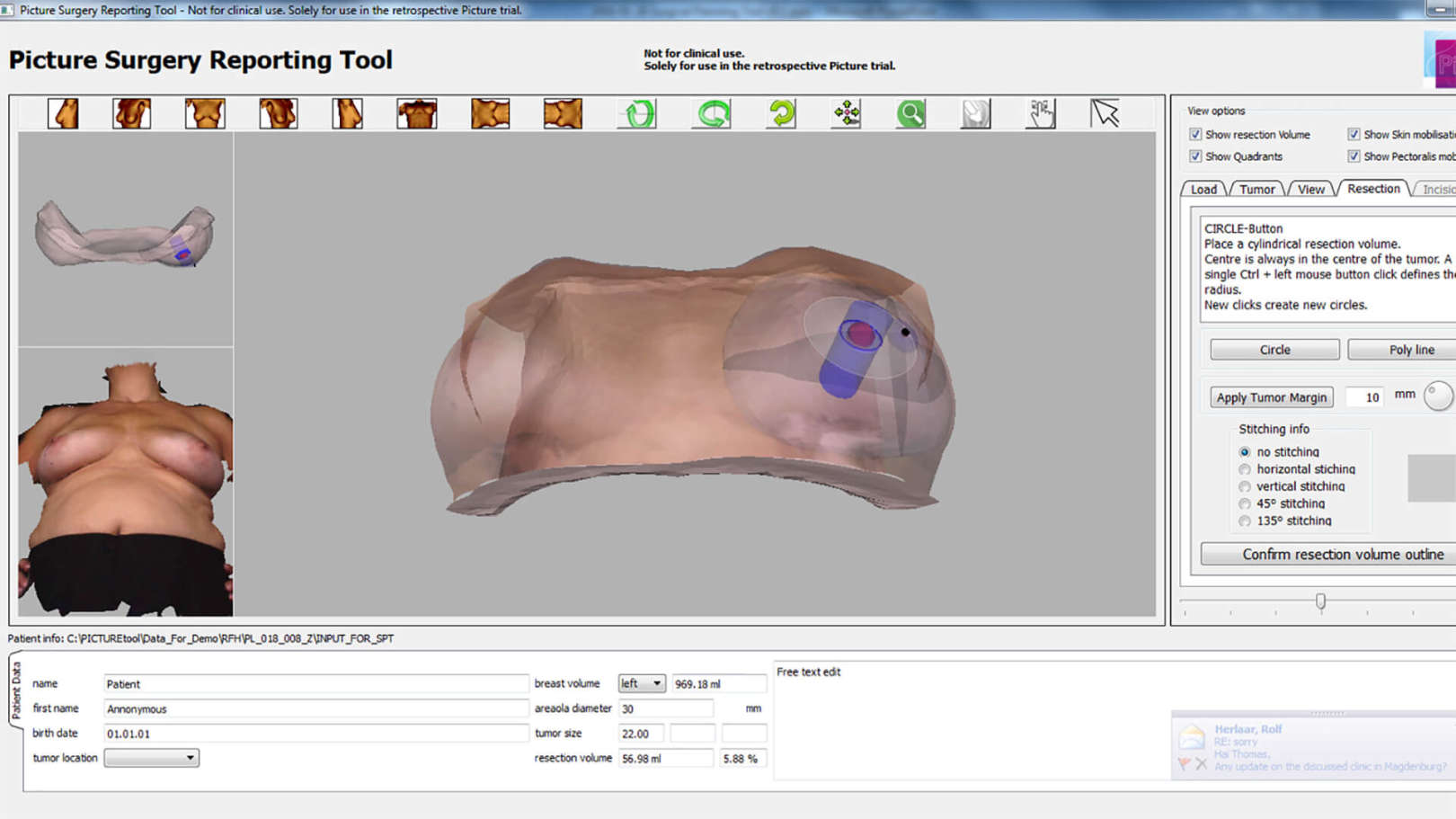
A sua investigação assenta em três grandes domínios: visão computacional, "machine learning" e sistemas de suporte à decisão. A investigação em processamento de imagem e vídeo tem abordado a área de biometria, imagem médica e "video tracking" para aplicações de vigilância e desportos. O trabalho em "machine learning" foca-se na adaptação de sistemas de aprendizagem às condições desafiantes de informação visual. A ênfase dos sistemas de suporte à decisão tem sido dirigida a aplicações médicas, sempre ancoradas com a análise automática de informação visual.
É co-autor de mais de 150 artigos, dos quais mais de 50 em jornais internacionais, com mais de 6500 citações (google scholar). Foi investigador principal em 6 projectos de I&D e participou em 14 projectos de I&D, incluindo 5 projectos europeus e um contrato directo com a BBC do Reino Unido.